 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROOFS: RObust biOmarker Feature Selection
Jan 08, 2026Feature selection (FS) is essential for biomarker discovery and in the analysis of biomedical datasets. However, challenges such as high-dimensional feature space, low sample size, multicollinearity, and missing values make FS non-trivial. Moreover, FS performances vary across datasets and predictive tasks. We propose roofs, a Python package available at https://gitlab.inria.fr/compo/roofs, designed to help researchers in the choice of FS method adapted to their problem. Roofs benchmarks multiple FS methods on the user's data and generates reports that summarize a comprehensive set of evaluation metrics, including downstream predictive performance estimated using optimism correction, stability, reliability of individual features, and true positive and false positive rates assessed on semi-synthetic data with a simulated outcome. We demonstrate the utility of roofs on data from the PIONeeR clinical trial, aimed at identifying predictors of resistance to anti-PD-(L)1 immunotherapy in lung cancer. The PIONeeR dataset contained 374 multi-source blood and tumor biomarkers from 435 patients. A reduced subset of 214 features was obtained through iterative variance inflation factor pre-filtering. Of the 34 FS methods gathered in roofs, we evaluated 23 in combination with 11 classifiers (253 models in total) and identified a filter based on the union of Benjamini-Hochberg false discovery rate-adjusted p-values from t-test and logistic regression as the optimal approach, outperforming other methods including the widely used LASSO. We conclude that comprehensive benchmarking with roofs has the potential to improve the robustness and reproducibility of FS discoveries and increase the translational value of clinical models.
Singing Language Identification using a Deep Phonotactic Approach
May 31, 2021

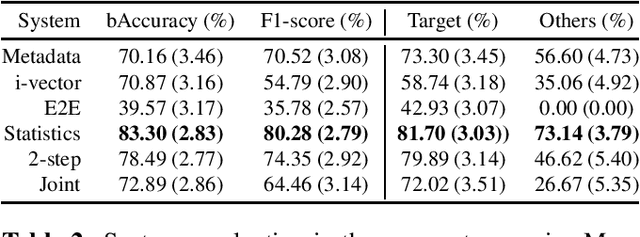

Extensive works have tackled Language Identification (LID) in the speech domain, however their application to the singing voice trails and performances on Singing Language Identification (SLID) can be improved leveraging recent progresses made in other singing related tasks. This work presents a modernized phonotactic system for SLID on polyphonic music: phoneme recognition is performed with a Connectionist Temporal Classification (CTC)-based acoustic model trained with multilingual data, before language classification with a recurrent model based on the phonemes estimation. The full pipeline is trained and evaluated with a large and publicly available dataset, with unprecedented performances. First results of SLID with out-of-set languages are also presented.
* 5 pages, 1 figure, ICASSP 2021